


🤖 Sentiment Analysis with Naive Bayes: Predicting Emotions in Tweets
Natural Language Processing(Part 21)

Learn how to perform sentiment analysis on tweets using the Naive Bayes algorithm. This hands-on tutorial covers tweet preprocessing, prediction, accuracy evaluation, and a Python code example.
📚Chapter 3: Sentiment Analysis (Naive Bayes)
If you want to read more articles about NLP, don’t forget to stay tuned :) click here.
Description
This part will be fun as you will apply the Naive Bayes classifier on real test examples. It is similar to what you did in the first Tutorial of the week, but we’ll cover some special corner cases. Once you have trained your model, the next step is to test it. You do so by taking the conditional probabilities you just derived. You use them to predict the sentiments of new unseen tweets. After that, you’ll evaluate your model performance, and you will do so just like how you did it in the last week. You use your test sets of annotated tweets.
Sections
Predicted the sentiment of a new tweet
Test the performance of your classifier on unseen data
Summary
Section 1- Predicted the sentiment of a new tweet,
With the calculations you’ve done already, you have a table with the Lambda score for each unique word in your vocabulary. With your estimation of the logprior, you can predict sentiments on a new tweet.

This new tweet says, “I passed the NLP interview.” You can use your model to predict if this is a positive or negative tweet. Before anything else, you must pre-process this text, removing the punctuation, stemming the words, and tokenizing to produce a vector of words like this one. Now, you look up each word from the vector in your log-likelihood table. If the word is found, such as I pass, the, and NLP, you sum over all the corresponding Lambda terms. The values that don’t show up in the table of Lambdas, like interview, are considered neutral and don’t contribute anything to the score. Your model can only give a score for words it’s seen before. Now, you add the log prior to account for the balance or imbalance of the classes in the datasets. This score sums up to 0.48.
Remember, if this score is bigger than 0, then this tweet has a positive sentiment. Yes, in your model and in real life, passing the NLP interview is a very positive thing. You just predicted the sentiment of a new tweet, and that’s awesome.
Section 2- Test the performance of your classifier on unseen data
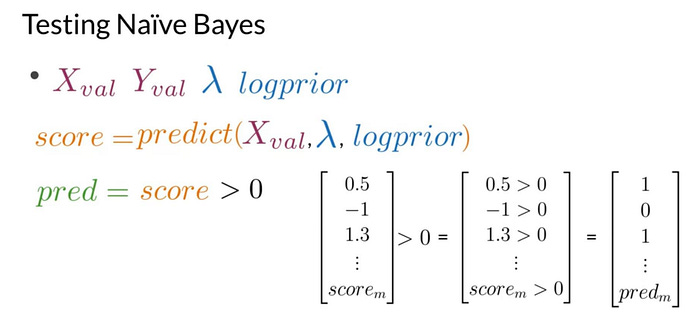
It’s time to test the performance of your classifier on unseen data, just like you already did for a different scenario in the previous module. Let’s quickly review that process as applied to Naive Bayes. This week’s assignments includes a validation set. This data was set aside during training and is composed of a set of raw tweets, so X_val and their corresponding sentiments Y_val. You’ll have to implement the accuracy function to measure the performance of your trained model, represented by the Lambda table and the logprior using these data. First, compute the score of each entry in X_val, like you just did previously. Then evaluate whether each score is greater than 0. This produces a vector populated with zeros and ones, indicating if the predicted sentiment is negative or positive respectively.For each tweet in the validation sets.

With your new predictions vector, you can compute the accuracy of your model over the validation sets. To do this part, you will compare your predictions against the true value for each observation from your validation data, Y-val. If the values are equal and your prediction is correct, you’ll get a value of one and zero if incorrect. Once you have compared the values of every prediction with the true labels of your validation sets, you can compute the accuracy as the sum of this vector divided by the number of examples in the validation sets, just like you did forthe logistic regression.
Section 3 Summary
Let’s revisit everything you just did. To test the performance of your Naive Bayes model, you use a validation set to allow you to predict the sentiment score for an unseen tweet using your newly trained model. Then you compared your predictions with the true labels provided in the validation setsto get the percentage of tweets that were correctly predicted by your label. Then you compared your predictions with the true labels provided in the validation sets. This allowed you to get the percentage of tweets that were correctly predicted by your model. You also saw that words that don’t appear in the Lambda table are treated as neutral words. Now you know how to apply the Naive Bayes method to test examples.
📚 Related Posts You’ll Love
How Naive Bayes and Bayes’ Rule Power Sentiment Analysis in NLP
Understanding Naive Bayes for Sentiment Analysis: Key Steps and Tips
🎯 Call to Action (CTA)
Ready to take your NLP skills to the next level?
✅ Try running the code example above in Jupyter Notebook or Colab
📬 Subscribe to our newsletter for weekly ML/NLP tutorials
⭐ Follow our GitHub repository for project updates and real-world implementations
🎁 Access exclusive NLP learning bundles and premium guides on our Gumroad store: From sentiment analysis notebooks to fine-tuning transformers—download, learn, and implement faster.
Source
1- Natural Language Processing with Classification and Vector Spaces