


📊 What Else Can Naive Bayes Do? From Tweet Sentiment to Spam Filters
Natural Language Processing (Part 22)

📚Chapter 3: Sentiment Analysis (Naive Bayes)
If you want to read more articles about NLP, don’t forget to stay tuned :) click here.
Introduction
Earlier in the tutorials, you used a Naive Bayes method to classify tweets. But that’s going to be used to do a number of things like identify who’s an author of a text. I’ll give you a few ideas of what those things may be.
Sections
Predict the sentiment of a tweet
Author Identity
Spam Filter
Information Retrieval
Word disambiguation
Introduction: Beyond Tweet Classification
You’ve probably seen Naive Bayes used for classifying tweets — like figuring out if a post is positive or negative. But that’s just one application. This simple and fast algorithm can handle a bunch of other text-based tasks, too. Let’s walk through a few of them.
🧠Sections 1- Predict the sentiment of a tweet
Sentiment analysis is one of the most common uses of Naive Bayes. The idea is to compute the probability of each sentiment class (like positive or negative) based on the words in the tweet.
The math behind it? Naive Bayes assumes words are independent given a class (which is rarely true in real life, but works surprisingly well). It calculates something like this:
P(class | words) ∝ P(class) * P(words | class)
Let’s try a simple example using Python and scikit-learn.
When you use Naive Bayes to predict the sentiment of a tweet, what you’re actually doing is estimating the probability for each class by using the joint probability of the words in classes. The Naive Bayes formula is as the ratio between these two probabilities, the products of the priors and the likelihoods. You can use this ratio between conditional probabilities for much more than sentiment analysis.

🧾Section 2- Author Identity
Imagine you have a stack of texts by Shakespeare and another by Hemingway. Could you tell who wrote a new paragraph? With Naive Bayes, yes.
You’d treat the author's identity as the class and calculate the probability of a document belonging to each author based on word usage. The author with the highest probability wins.
This approach is great for:
Stylometry (identifying writing style)
Authorship verification
Literary analysis
For one, you could do author identification. If you had two large corporal, each written by different authors, you could train a model to recognize whether a new document was written by one or the other. Or if you had some works by Shakespeare and some works by Hemingway, you could calculate the Lambda for each word to predict how likely a new word is to be used by Shakespeare or alternatively by Hemingway. This method also allows you to determine author Identity.

🚫Section 3- Spam Filter
This one’s a classic.
Spam filters often use Naive Bayes to classify emails based on:
Sender info
Subject line
Message content
The model learns what words are common in spam versus real messages and flags future emails accordingly.
Gmail? Outlook? Most email providers still rely on a version of this under the hood.
Another common use is spam filtering. Using information taken from the sender, subjects and content, you could decide whether an email is spam or not.
🔍Section 4- Information Retrieval
Before Google became what it is, Naive Bayes was used to match queries to relevant documents. The idea? Rank documents based on how likely they are to contain the query keywords.
You don’t always know what a "relevant" document looks like upfront — but you can still compute the likelihood of each one being useful. Then:
Keep the top
mdocuments, orFilter those above a certain probability threshold
Simple but effective.
One of the earliest uses of Naive Bayes was filtering between relevant and irrelevant documents in a database given the sets of keywords in a query. In this case, you only needed to calculate the likelihood of the documents given the query. You can’t know beforehand what’s a relevant or irrelevant document looks like. You can compute the likelihood for each document in your dataset and then store the documents based on its likelihoods. You can choose to keep the first m results or the ones that have a likelihood larger than a certain threshold.
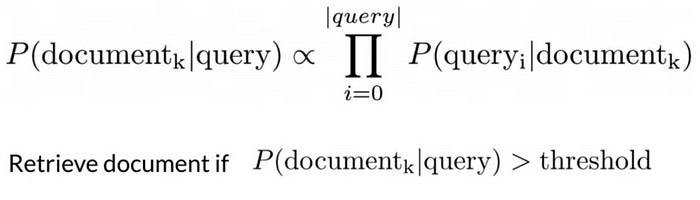
🤔Section 5- Word disambiguation
Finally, let’s talk about ambiguous words — like “bank”. Is it a riverbank or a financial institution?
Naive Bayes can help disambiguate words by looking at context. For example:
If nearby words include "money", it’s probably a financial bank.
If you see "water" or "shore", it might refer to a riverbank.
You compare probabilities for both meanings based on context — and go with the higher score.
Finally, you can also use Naive Bayes for word disambiguation, which is to say, breaking down words for contextual clarity. Consider that you have only two possible interpretations of a given word within a text. Let’s say you don’t know if the word bank in your reading is referring to the bank of a river or to a financial institution. To disambiguate your word, calculate the score of the documents, given that it refers to each one of the possible meanings. In this case, if the texts refers to the concept of river, instead of the concept of money, then the score will be bigger than one. That’s cool, right? In summary, Bayes rule and it’s Naive approximation has a wide range of applications in sentiment analysis, author identification, information retrieval, and word disambiguation. It’s a popular method since it’s relatively simple to train use and interpret. You’ll be using the Bayes rule and Naive Bayes again in the weeks ahead. Now, you’re fully equipped. As you’ve seen in this video, Naive Bayes can be used for many classification tasks. Next, I’ll show you the assumptions that underlie the Naive Bayes method.

⚙️ Wrapping Up: Naive Bayes Is Surprisingly Versatile
You’ve seen how Naive Bayes isn’t just for basic classification tasks. It can power:
Tweet sentiment analysis
Author identification
Spam filtering
Document retrieval
Word disambiguation
It’s fast, easy to train, and works well even with small data — making it a great baseline for NLP tasks.
🔗 Related Posts You Might Like
🎯 Call to Action (CTA)
Ready to take your NLP skills to the next level?
✅ Try running the code example above in Jupyter Notebook or Colab
📬 Subscribe to our newsletter for weekly ML/NLP tutorials
⭐ Follow our GitHub repository for project updates and real-world implementations
🎁 Access exclusive NLP learning bundles and premium guides on our Gumroad store: From sentiment analysis notebooks to fine-tuning transformers—download, learn, and implement faster.
Source
1- Natural Language Processing with Classification and Vector Spaces