


Logistic Regression in Deep Learning: Key Concepts, Applications, and Insights
DL (Part 6)

📚Chapter2: Logistic Regression as a Neural Network
Learn how logistic regression serves as a foundation for deep learning. This guide covers its mathematical formulation, decision boundaries, sigmoid function, and real-world applications in disease diagnosis, customer churn prediction, and sentiment analysis
If you want to read more articles about Deep Learning, don’t forget to stay tuned :) click here.
Description
In the realm of deep learning, logistic regression is a fundamental concept that serves as the building block for more complex models. In this blog post, we will delve into the intricacies of logistic regression and explore its significance in deep learning. We will cover the basics of logistic regression, its mathematical formulation, the intuition behind it, and its practical applications. By the end of this article, you will have a comprehensive understanding of logistic regression and its role in deep learning.
Section 1- Introduction of Logistic Regression
Logistic regression is a classification algorithm. More specifically it’s a binary classification problem. It can also be converted into a multi-class classification algorithm. It is originally adopted from statistics and implemented as a machine-learning algorithm. Using nonlinearity, logistic regression classifies data points into classes. Additionally, it uses a logistic function to learn weights to classify data points in classes. The logistic function resembles an “S” shaped curve. This “S” shaped curve acts as the boundary of two classes. It is a supervised classification algorithm.
Logistic regression is a method for predicting binary outcomes, such as “yes” or “no” or “true” or “false,” as opposed to linear regression, which is used to predict continuous outcomes. The logistic function, which converts any input with a real value to a number between 0 and 1, serves as the foundation for the logistic regression model.
Logistic regression is a statistical model used to predict binary outcomes. It is widely employed in machine learning and serves as the foundation for more advanced models. Unlike linear regression, which predicts continuous values, logistic regression deals with categorical data. The goal is to determine the probability of an event occurring by fitting the input data to a sigmoid curve.
Section 2- Why do We Need Logistic Regression?
It is a popular classification method used in Machine Learning. It is also used as the sigmoid activation function in Deep Learning. Also, it helps to generalize the model better by adding nonlinearity to the network.
Section 3- How does Logistic Regression Work?
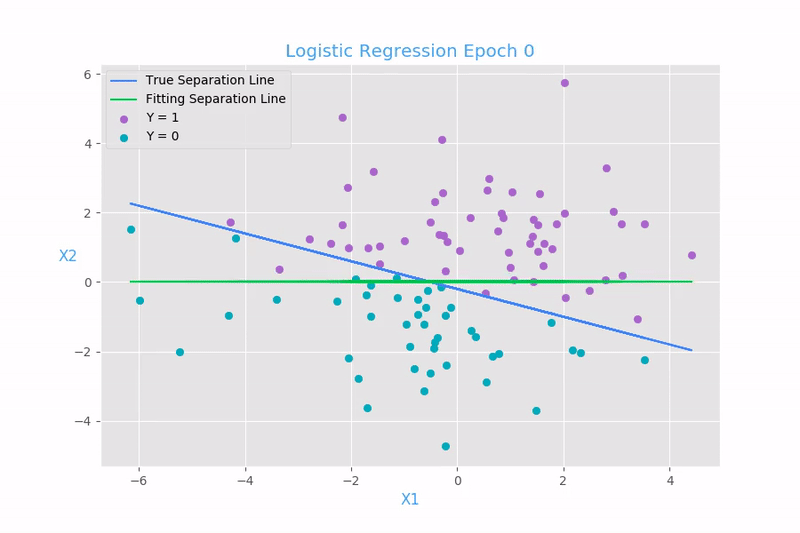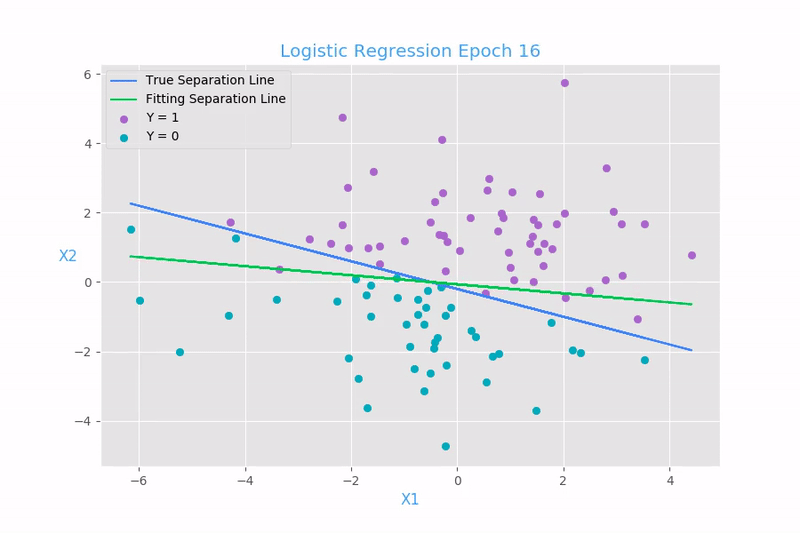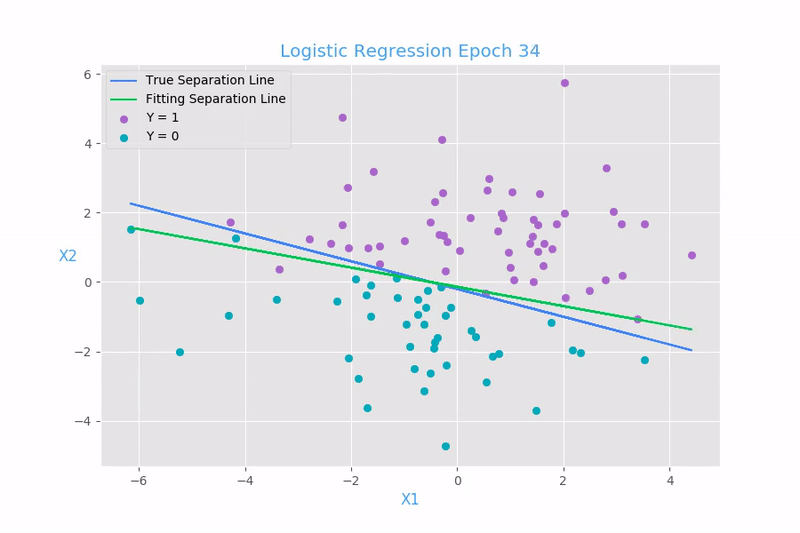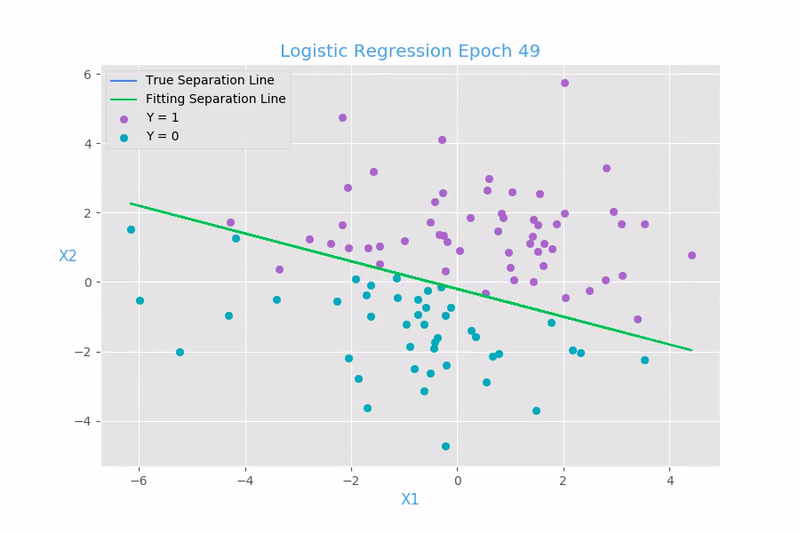
The intuition behind logistic regression lies in the concept of decision boundaries. By fitting a sigmoid curve to the data, logistic regression creates a decision boundary that separates the two classes. Points falling on one side of the boundary are classified as one class, while points on the other side are classified as the other class. The decision boundary is determined by the weights and bias terms in the logistic regression equation. By adjusting these parameters during training, the model learns to find the optimal decision boundary that minimizes classification errors.
Logistic regression converts the data in a range of 0 to 1 to predict the class it belongs to. If the value is less than 0.5 then it belongs to class 0 and if the value is greater than 0.5 then it is classified as class 1. As the name suggests logistic regression is derived from its calculation which converts it into logits i.e. 0 or 1.
Logistic regression gives the probability for the predicted class which lies between 0 and 1. The greater the prediction probability, higher the chance that it belongs to the predicted class
In this tutorial, we’ll go over logistic regression. This is a learning algorithm that you use when the output labels Y in a supervised learning problem are all either zero or one, so for binary classification problems.
Given an input feature vector X may correspond to an image that you want to recognize as either a cat picture or not a cat picture, you want an algorithm that can output a prediction, which we’ll call Y hat, which is your estimate of Y. More formally, you want Y hat to be the probability of the chance that Y is equal to one given the input features X. So in other words, if X is a picture, as we saw in the last tutorial, you want Y hat to tell you, what is the chance that this is a cat picture? So X, as we said in the previous tutorial, is an X-dimensional vector, given that the parameters of logistic regression will be W which is also a dimensional vector, together with b which is just a real number. So given an input X and the parameters W and b, how do we generate the output Y hat? Well, one thing you could try, that doesn’t work, would be to have Y transposed X plus B, kind of a linear function of the input X. And in fact, this is what you use if you were doing linear regression. But this isn’t a very good algorithm for binary classification because you want Y hat to be the chance that Y is equal to one. So Y hat should really be between zero and one, and it’s difficult to enforce that because W transpose X plus B can be much bigger than one or it can even be negative, which doesn’t make sense for probability. That you want it to be between zero and one.

So in logistic regression, our output is instead going to be Y hat equals the sigmoid function applied to this quantity. This is what the sigmoid function looks like. If on the horizontal axis I plot Z, then the function sigmoid of Z looks like this. So it goes smoothly from zero up to one. Let me label my axes here, this is zero and it crosses the vertical axis as 0.5. So this is what sigmoid of Z looks like. And we’re going to use Z to denote this quantity, W transpose X plus B. Here’s the formula for the sigmoid function. Sigmoid of Z, where Z is a real number, is one over one plus E to the negative Z. So notice a couple of things. If Z is very large, then E to the negative Z will be close to zero. So then sigmoid of Z will be approximately one over one plus something very close to zero, because E to the negative of very large number will be close to zero. So this is close to 1. And indeed, if you look in the plot on the left, if Z is very large the sigmoid of Z is very close to one. Conversely, if Z is very small, or it is a very large negative number, then sigmoid of Z becomes one over one plus E to the negative Z, and this becomes, it’s a huge number. So this becomes, think of it as one over one plus a number that is very, very big, and so, that’s close to zero. And indeed, you see that as Z becomes a very large negative number, sigmoid of Z goes very close to zero. So when you implement logistic regression, your job is to try to learn parameters W and B so that Y hat becomes a good estimate of the chance of Y being equal to one. Before moving on, just another note on the notation. When we programmed neural networks, we’ll usually keep the parameter W and parameter B separate, where here, B corresponds to an inter-spectrum. In some other courses, you might have seen a notation that handles this differently. In some conventions you define an extra feature called X0 and that equals a one. So that now X is in R of NX plus one. And then you define Y hat to be equal to sigma of theta transpose X. In this alternative notational convention, you have vector parameters theta, theta zero, theta one, theta two, down to theta NX And so, theta zero, place a row a B, that’s just a real number, and theta one down to theta NX play the role of W. It turns out, when you implement your neural network, it will be easier to just keep B and W as separate parameters. And so, in this class, we will not use any of these notational convention that I just wrote in red. If you’ve not seen this notation before in other courses, don’t worry about it. It’s just that for those of you that have seen this notation I wanted to mention explicitly that we’re not using that notation in this course. But if you’ve not seen this before, it’s not important and you don’t need to worry about it. So you have now seen what the logistic regression model looks like. Next to change the parameters Wand B you need to define a cost function.
Section 4- Practical Applications
Logistic regression finds applications in various fields due to its simplicity and interpretability. Some practical applications include:
Disease diagnosis: Logistic regression can be used to predict whether a patient has a certain disease based on their symptoms and medical history.
Customer churn prediction: Logistic regression can help identify customers who are likely to churn from a service or product.
Sentiment analysis: Logistic regression can classify text data as positive or negative sentiment.
Credit scoring: Logistic regression can assess creditworthiness based on demographic and financial information.
Section 5- Advantages and Limitations
Logistic regression offers several advantages in deep learning:
Simplicity: Logistic regression is relatively simple to understand and implement compared to more complex models.
Interpretability: The coefficients in logistic regression provide insights into feature importance and direction of influence.
Efficiency: Logistic regression can handle large datasets efficiently.
However, it also has limitations:
Linearity assumption: Logistic regression assumes a linear relationship between features and log odds.
Sensitivity to outliers: Outliers can significantly impact logistic regression models.
Limited modeling power: Logistic regression may not capture complex relationships present in data.
Section 6: Conclusion
Logistic regression forms an essential component of deep learning models and serves as a powerful tool for binary classification problems. With its intuitive formulation, optimization techniques, regularization methods, and practical applications, logistic regression provides a solid foundation for understanding more advanced concepts in deep learning. By grasping the fundamentals of logistic regression, you can unlock a world of possibilities in machine learning and data analysis.
Please Follow and 👏 Subscribe Coursesteach for details of Deep Learning
🚀 Elevate Your Data Skills with Coursesteach! 🚀
Ready to dive into Python, Machine Learning, Data Science, Statistics, Linear Algebra, Computer Vision, and Research? Coursesteach has you covered!
🔍 Python, 🤖 ML, 📊 Stats, ➕ Linear Algebra, 👁️🗨️ Computer Vision, 🔬 Research — all in one place!
Join the full course for More Learning!🌟

Neural Networks and Deep Learning course
Improving Deep Neural Network course
Stay tuned for our upcoming articles because we reach end to end ,where we will explore specific topics related to Deep Learning in more detail!
We offer following serveries:
We offer the following options:
Enroll in my Deep Learning course: You can sign up for the course at this link. The course is designed in a blog-style format and progresses from basic to advanced levels.
Access free resources: I will provide you with learning materials, and you can begin studying independently. You are also welcome to contribute to our community — this option is completely free.
Online tutoring: If you’d prefer personalized guidance, I offer online tutoring sessions, covering everything from basic to advanced topics.
Contribution: We would love your help in making coursesteach community even better! If you want to contribute in some courses , or if you have any suggestions for improvement in any coursesteach content, feel free to contact and follow.
Together, let’s make this the best AI learning Community! 🚀
Source
1- Neural Networks and Deep Learning
2- 17 Unique Machine Learning Interview Questions on Logistic Regression
4-Visual Guide to Logistic Regression
5- 17 Unique Machine Learning Interview Questions on Logistic Regression