


Data Encoding in Machine Learning: A Comprehensive Guide to Transforming Categorical Data for Better Model Performance
Supervised learning with scikit-learn (Part 9)

📚Chapter:3-Data Preprocessing and Pipelines
Stay Tuned!
If you want to read more articles about Supervised Learning with Scikit-Learn, don’t forget to stay tuned! Click here to explore more.
Introduction
In the vast realm of machine learning, data is the lifeblood that fuels models, algorithms, and predictions. However, raw data is often messy, diverse, and incompatible with the mathematical machinery of machine learning algorithms.Machine learning models require all input and output variables to be numeric. This means that if your data contains categorical data, you must encode it to numbers before you can fit and evaluate a model. This is where data encoding comes into play. In this blog post, we’ll unravel the intricacies of data encoding, its significance in machine learning, and the various techniques employed to transform raw data into a format that can be effectively utilized by models.

Sections
What is meant by Data Transformation?
What is meant by Data Encoding?
Why is Data Encoding Necessary in Machine Learning ?
What is meant by Categorical data?
Type of Categorical data
Handling Categorical Labels
Challenges and Best Practices:
How to check if a column of strings contains any numbers that have been encoded as strings?
Machine learning algorithem that working on categorical data
Conclusion
Section 1- What is meant by Data Transformation?
Def: Changing data from one format to another without altering the content is referred to as data transformation. Data preparation or processing is one of the most important steps when working with real-world data on a machine-learning project. Since the ML model works on maths and numbers, so it’s necessary we encode these categorical variables into numbers. One of the major pains in such situations is working with categorical data. This is because most of the machine learning algorithms cannot work with categorical data directly. They need to be converted to numerical data.
Section 2- What is meant by Data Encoding?
Def: Data encoding is the process of converting data from one form to another, making it suitable for a specific purpose. In the context of machine learning, this involves transforming raw, unstructured data into a structured format that can be fed into algorithms for training and prediction.
Section 3- Why is Data Encoding Necessary in Machine Learning ?
Machine learning algorithms operate on mathematical principles, and they require input data to be in a consistent and numerical format. Raw data, such as text, categorical variables, or dates, needs to be encoded into numerical representations to be compatible with these algorithms.
Encoding categorical data into numerical format is a critical preprocessing step for most machine learning algorithms. Since many models require numerical input, the choice of encoding technique can significantly impact performance. A well-chosen encoding strategy enhances accuracy, while a suboptimal approach can lead to information loss and reduced model performance.
Section 4- What is meant by Categorical data?
Data Science is the art and science of solving real-world problems and making data-driven decisions. It primarily deals with all kinds of structured or unstructured data. Data, broadly, can be divided into two types i.e., Numerical and Categorical. Most of the data science models are equipped to work with numerical data; however, things get interesting when we have to deal with Categorical data.
Categorical data are variables that contain label values rather than numeric values
Def: Categorical data is a form of data that takes on values within a finite set of discrete classes. It is difficult to count or measure categorical data using numbers and therefore they are divided into categories. An example of categorical data would be the Gender of a person. It can only take values between Male, Female, and Others.
Section 5- Type of Categorical data
Here’s where things get interesting: not all categorical data is the same. You’ve got nominal and ordinal data.
I. Ordinal Variables:
These variables maintain a natural order in their class of values. If we consider the level of education then we can easily sort them according to their education tag in the order of High School < Under-Graduate<post-Graduate < PhD. The review rating system can also be considered as an ordinal data type where 5 stars is definitely better than 1 star.
II. Nominal Variables:
These variables do not maintain any natural/logical order. The color of a car can be considered as Nominal Variable as we cannot compare the color with each other. It is impossible to state that “Red” is better than “Blue” (subjective!). Similarly, Gender is a type of Nominal Variable as again we cannot differentiate between Male, Female, and Others.
This distinction matters a lot when choosing between one hot encoding and label encoding. Why? Because the wrong encoding could mess with how your algorithm interprets this data.
Section 6- Handling Categorical Labels
Say you are dealing with a dataset that has categorical features, such as ‘red’ or ‘blue’, or ‘male’ or ‘female’. As these are not numerical values, the scikit-learn API will not accept them and you will have to preprocess these features into the correct format. Our goal is to convert these features so that they are numerical. The way we achieve this by splitting the feature into a number of binary features called ‘dummy variables, one for each category: ‘0’ means the observation was not that category, while ‘1’ means it was.
Nominal encoding
Ordinal encoding
Label Encoding
One-Hot Encoding
Binary Encoding
Frequency Encoding
Embedding
1- Nominal Encoding
When we have a feature where variables are just names and there is no order or rank to this variable’s feature [2].
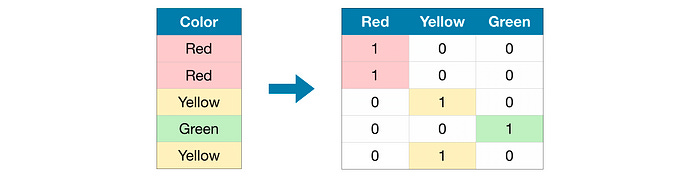
In the above example, We do not have any order or rank, or sequence. All the variables in the respective feature are equal. We can’t give them any orders or ranks. Those features are called Nominal features [2].
2. Ordinal Encoding:
When we have a feature where variables have some order/rank. Ordinal encoding is employed when there is an inherent order or rank among categories. It assigns numerical values based on the order, preserving the ordinal relationship in the data.
Each label for a categorical variable can be mapped to a unique integer, called an ordinal encoding The ordinal encoder is the most suitable option for encoding ordinal variables. It helps the machine learning model to establish a relationship between a categorical column and the target column. For example, if we want to predict the salary of an employee, it would depend on different features, and education level would be one of those features. Now, logically the one with a Ph.D. will have a better salary than the one with a high school degree. so, the model will learn that a Ph.D. with a value of 3 in the data frame weighs more than the one with a high school degree with a value of 0. This way the model will learn that when the level of education goes up, the salary increases and vice versa [4].

For example: Student’s performance, Customer’s review, Education of person, etc In the above example, we have orders/ranks/sequences. We can assign ranks based on student’s performance, based on feedback given by customers, based on the highest education of the person. Those features are called Ordinal features.
Python Implementation
[OrdinalEncoder(categories=[[‘HS’, ‘AS’, ‘M.S’, ‘Ph.D.’]])]
df['Education'].unique()
from sklearn.preprocessing import OrdinalEncoder
ordinal = OrdinalEncoder(categories=[['HS', 'AS', 'M.S','Ph.D']])
df['Education'] = ordinal.fit_transform(df[['Education']])
df.head()
3- One-Hot Encoding
Here’s how it goes: for every unique category in your data, one hot encoding creates a new binary column. So, instead of having one column with several categorical values, you’ll have multiple columns — each representing a category.
In machine learning, “one-hot encoding” is a technique used to represent categorical variables as binary vectors.
Each category is assigned a unique binary code, where only one bit is ‘hot’ (1), and the others are ‘cold’ (0). This method ensures that the model understands the categorical distinctions without implying any ordinal relationship between the categories.
For instance, in a color category with red, green, and blue, one-hot encoding would represent them as [1, 0, 0], [0, 1, 0], and [0, 0, 1], respectively. This simplifies computations and aids in effective model training.
One-Hot Encoding takes a single integer and produces a vector where a single element is 1 and all other elements are 0, like [0,1,0,0][0,1,0,0]. For example, imagine we’re working with categorical data, where only a limited number of colors are possible: red, green, or blue. One way we could represent this numerically is by assigning each color a number [5].

This is known as integer encoding. For Machine Learning, this encoding can be problematic — in this example, we’re essentially saying “green” is the average of “red” and “blue”, which can lead to weird unexpected outcomes. It’s often more useful to use the one-hot encoding instead [5]:

Disadvantages
If there is no ordinal relationship between the categorical variables then ordinal encoding might mislead the model.This is because the ordinal encoder will try to force an ordinal relationship on the variables to assume a natural ordering, thus resulting in poor performance.
Advantages
One-hot encoding is particularly used in those cases where there is no ordinal relationship between the labels.
Exaplanation
In this case, One Hot encoder should be used to treat our categorical variables. It will create dummy variables by converting N categories into N features/columns. Considering the gender column again. If we have a male in the first row, then its value is 1. Also if we have a female in the second row then its value is 0. Whenever the category exists its value is 1 and 0 where it does not.
Methods
We can one-hot encode categorical variables in two ways. One, by using get_dummies in pandas and two, by using OneHotEncoder from sklearn [4].
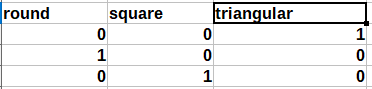
In one-hot encoding, the numerical variables are replaced by binary variables. So, each of the categories is either 0 or 1. Again, take the shape category example into account. If the shape is, say, ‘triangle‘, then it is labeled as 1 and all other shapes are labeled as zero. The following image may clear some things up[3].
Then, a one hot encoding can be applied to the ordinal representation. This is where one new binary variable is added to the dataset for each unique integer value in the variable, and the original categorical variable is removed from the dataset. For example, imagine we have a color variable with three categories (red, green, and blue). In this case, three binary variables are needed. A “1” value is placed in the binary variable for the color and “0” values for the other colors.
This one hot encoding transform is available in the scikit-learn Python machine learning library via the OneHotEncoder class. The breast cancer dataset contains only categorical input variables. The example below loads the dataset and one hot encodes each of the categorical input variables.
One-Hot Encoding in Python
# one hot encode the breast cancer dataset
from pandas import read_csv
from sklearn.preprocessing import OneHotEncoder
# define the location of the dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv"
# load the dataset
dataset = read_csv(url, header=None)
# retrieve the array of data
data = dataset.values
# separate into input and output columns
X = data[:, :-1].astype(str)
y = data[:, -1].astype(str)
# summarize the raw data
print(X[:3, :])
# define the one hot encoding transform
encoder = OneHotEncoder(sparse=False)
# fit and apply the transform to the input data
X_oe = encoder.fit_transform(X)
# summarize the transformed data
print(X_oe[:3, :])1- get_dummies
Say you are dealing with a dataset that has categorical features, such as ‘red’ or ‘blue’, or ‘male’ or ‘female’. As these are not numerical values, the scikit-learn API will not accept them and you will have to preprocess these features into the correct format. Our goal is to convert these features so that they are numerical. The way we achieve this by splitting the feature into a number of binary features called ‘dummy variables, one for each category: ‘0’ means the observation was not that category, while ‘1’ means it was.
For example, say we are dealing with a car dataset that has a ‘origin’ feature with three different possible values: ‘US’, ‘Asia’, and ‘Europe’.
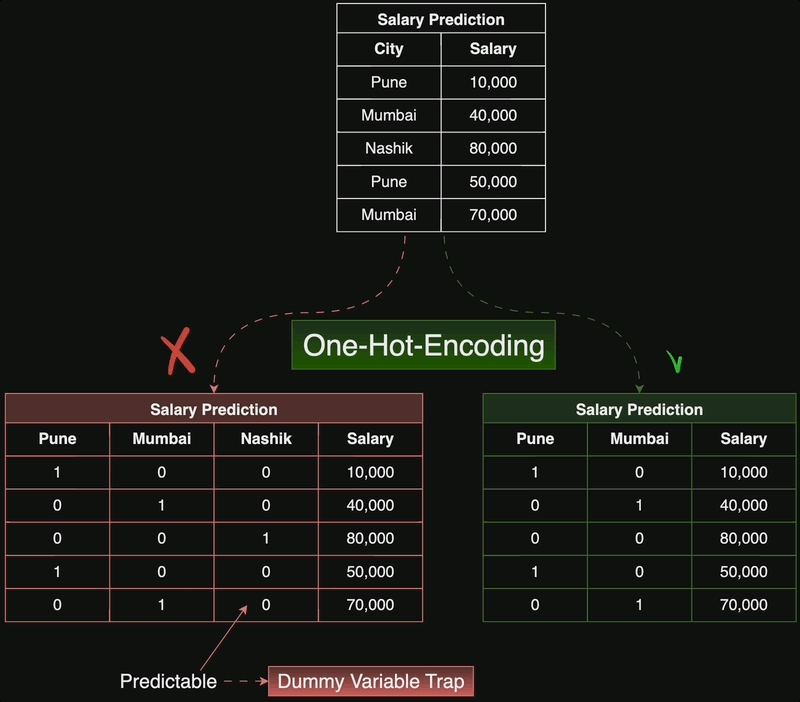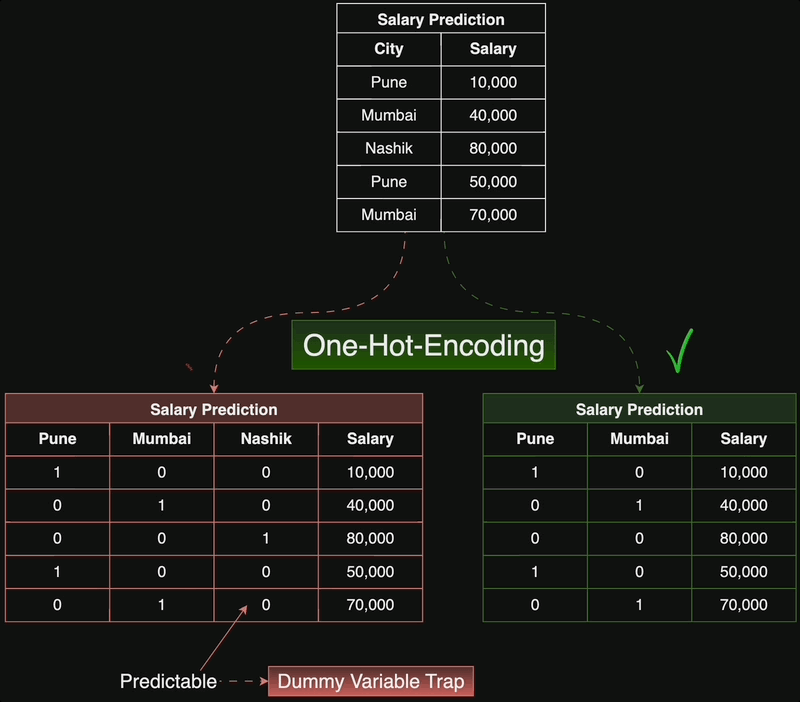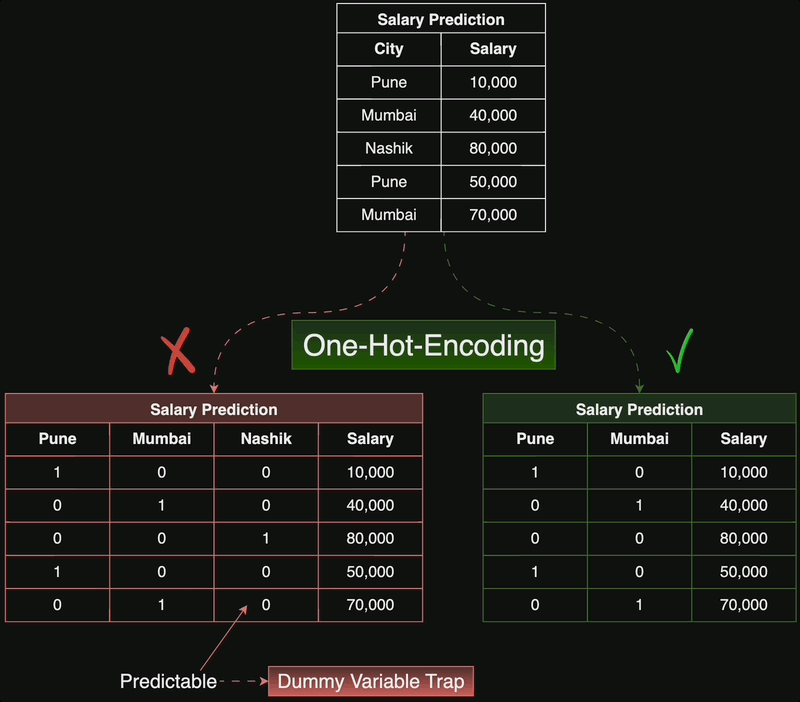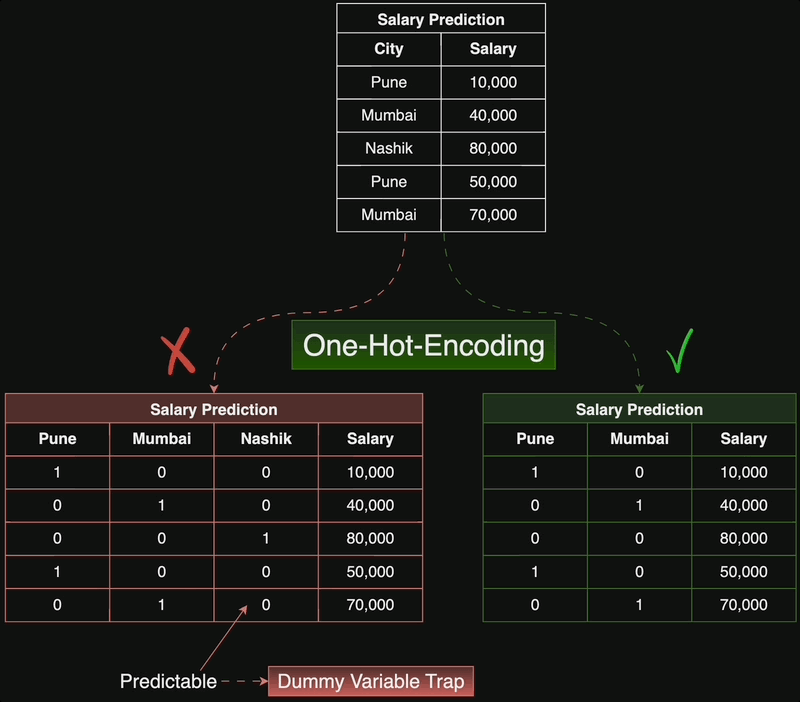
We create binary features for each of the origins, as each car is made in exactly one country, each row in the dataset will have a one in exactly one of the three columns and zeros in the other two. Notice that in this case, if a car is not from the US and not from Asia, then implicitly, it is from Europe. That means that we do not actually need three separate features, but only two, so we can.
delete the ‘Europe’ column. If we do not do this, we are duplicating information, which might be an issue for some models.
We import pandas, read in the DataFrame, and then apply the get dummies function. Notice, how pandas creates three new binary features. In the third row, origin USA and origin Europe have zeroes, while origin Asia has a one, indicating that the car is of Asian origin. But if origin USA and origin Europe are zero, then we already know that the car is Asian!


pd.get_dummies(df['Gender']).head()
Another example is Marital Status. Here, we have three different categories Married: M, Divorced: D, and Single: S. we can reduce the dimensionality by one column by using: “drop_first=True” meaning the number of columns will be one less than the number of categories [4].
pd.get_dummies(df['Marital Status'],drop_first=True).head()
In the second row of the table above, we have zero for married and single, which effectively means that it is Divorced. If we assign drop_first =False, then we still have three columns: Married, Single, and Divorced [4].
pd.get_dummies(df['Marital Status'],drop_first=False).head()
2- OneHotEncoder
Example 1
As mentioned, we can also implement one-hot encoding through OneHotEncoder from sklearn [4].
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
ohe.fit_transform(df0[['Marital Status']])If we have a high number of categorical variables in a column, then we should avoid using one-hot encoding. It will result in an increase in the number of corresponding columns which will give rise to a problem called “Curse of Dimensionality”[4].
Example 2
oversampled.select_dtypes(include=['object']).columns
# Impute categorical var with Mode
oversampled['MRNO'] = oversampled['MRNO'].fillna(oversampled['MRNO'].mode()[0])
oversampled['AGE'] = oversampled['AGE'].fillna(oversampled['AGE'].mode()[0])
oversampled['GENDER'] = oversampled['GENDER'].fillna(oversampled['GENDER'].mode()[0])
oversampled['DISTRICT'] = oversampled['DISTRICT'].fillna(oversampled['DISTRICT'].mode()[0])
oversampled['TEHSIL'] = oversampled['TEHSIL'].fillna(oversampled['TEHSIL'].mode()[0])
oversampled['REPORT_VERIFIED'] = oversampled['REPORT_VERIFIED'].fillna(oversampled['REPORT_VERIFIED'].mode()[0])
oversampled['RESULT_VALUE'] = oversampled['RESULT_VALUE'].fillna(oversampled['RESULT_VALUE'].mode()[0])# Convert categorical features to continuous features with Label Encoding
from sklearn.preprocessing import LabelEncoder
lencoders = {}
for col in oversampled.select_dtypes(include=['object']).columns:
lencoders[col] = LabelEncoder()
oversampled[col] = lencoders[col].fit_transform(oversampled[col])import warnings
warnings.filterwarnings("ignore")
# Multiple Imputation by Chained Equations
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
MiceImputed = oversampled.copy(deep=True)
mice_imputer = IterativeImputer()
MiceImputed.iloc[:, :] = mice_imputer.fit_transform(oversampled)Example 3
from sklearn.preprocessing import OneHotEncoderencoder = OneHotEncoder(sparse=False)
print(encoder.fit_transform([['red'], ['green'], ['blue']]))
'''
[[0. 0. 1.]
[0. 1. 0.]
[1. 0. 0.]]Label Encoding
The label encoder will convert each category into a unique numerical value. If implemented with Sklearn, then this encoder should be used to encode output values, i.e. y, and not the input X. It is similar to the ordinal encoder except, here the numeric values are assigned automatically without following any sort of natural order. Generally, the alphabetical order of the categorical values is used to determine which numerical value comes first. Considering our target variable “Job Status” column has four different categories. After applying label encoding to this column the four different categories are mapped into integers 0: Full Time, 1: Intern, 2: Part-Time, and 3:Unemployed. With this, it can be interpreted that the Unemployed have a higher priority than Part-Time, Full Time, and Intern while training the model, whereas, there is no such priority or relation between these statuses. We can’t define the order of labels with the label encoding technique[4].
from sklearn.preprocessing import LabelEncoder
lbe = LabelEncoder()
df['Employment Status']= lbe.fit_transform(df['Employment Status'])
df.head()
Disadvantages
it gives an order to the categorical value, which might not be suitable to some machine learning algorithms such as Linear Regression, as they are too sensitive to the values; in such case, one hot encoding provides better results [4].
Advantages
On the other hand, label encoding is suitable with Decision Tree and Random Forest algorithms because they don’t depend on the values of the categorical variables[4].
This process is okay until the number of labels is considerably small. When the number of labels increases, this solution may not work very well[3].
import seaborn as sns
df=sns.load_dataset('titanic')
import numpy as npSo, I am considering categorical features and will try to find out the top important features. Creating a data frame for categorical features. We need to compare all the categories with the output category (Survived).
##['sex','embarked','alone','pclass','Survived']
df=df[['sex','embarked','alone','pclass','survived']]
df.head()Let’s perform label encoding on the embarked
df['sex']=np.where(df['sex']=="male",1,0)
df.head()Let’s perform label encoding on the embarked
import numpy as np
### let's perform label encoding on embarked
ordinal_label = {k: i for i, k in enumerate(df['embarked'].unique(), 0)}
df['embarked'] = df['embarked'].map(ordinal_label)#Performing label encoding on alone
## let's perform label encoding on alone
df['alone']=np.where(df['alone']==True,1,0)3. Binary Encoding:
Binary encoding is useful for categorical variables with a large number of categories. It represents each category with binary code, reducing the dimensionality of the data compared to one-hot encoding.
5. Frequency Encoding:
Frequency encoding uses the frequency of each category in the dataset as its numerical representation. This can be beneficial when the frequency of categories carries important information.
6. Embedding:
In the case of natural language processing (NLP) and deep learning, word embeddings are used to represent words as vectors in a continuous vector space. This technique captures semantic relationships between words and is crucial in tasks like sentiment analysis and language translation.
7-Discretization transform
One approach is to use the transform of the numerical variable to have a discrete probability distribution where each numerical value is assigned a label and the labels have an ordered (ordinal) relationship. This is called a discretization transform and can improve the performance of some machine learning models for datasets by making the probability distribution of numerical input variables discrete. The discretization transform is available in the scikit-learn Python machine learning library via the KBinsDiscretizer class. It allows you to specify the number of discrete bins to create (n_bins), whether the result of the transform will be an ordinal or one hot encoding (encode), and the distribution used to divide up the values of the variable (strategy), such as ‘uniform’.The example below creates a synthetic input variable with 10 numerical input variables, then encodes each into 10 discrete bins with an ordinal encoding.
# discretize numeric input variables
from sklearn.datasets import make_classification
from sklearn.preprocessing import KBinsDiscretizer
# define dataset
X, y = make_classification(n_samples=1000, n_features=5, n_informative=5, n_redundant=0, random_state=1)
# summarize data before the transform
print(X[:3, :])
# define the transform
trans = KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform')
# transform the data
X_discrete = trans.fit_transform(X)
# summarize data after the transform
print(X_discrete[:3, :])Section 7-Challenges and Best Practices:
1. Handling Missing Data:
Data encoding must address missing values appropriately. Imputation techniques or dedicated encoding for missing values can be employed based on the nature of the data.
2. Scaling and Normalization:
Numeric features might have different scales, impacting the performance of some algorithms. Scaling and normalization techniques, such as Min-Max scaling or Z-score normalization, ensure all features contribute equally to model training.
3. Robustness to Changes:
Data encoding strategies should be chosen carefully to ensure the model’s robustness to changes in the input data. For example, adding a new category should not break the encoding schema.
Section 8- How to check if a column of strings contains any numbers that have been encoded as strings?
This is a good one for data cleaning or feature engineering — say you’re trying to get numbers out of a column or replace them.[1]
# Syntax
df[df.column.str.contains("\d+", na=False)]
# Example
titanic[titanic.Tickets.str.contains("\d+", na=False)]Section 9- Machine learning algorithem that working on categorical data?
Some machine learning algorithms may prefer or require categorical or ordinal input variables, such as some decision tree and rule-based algorithms. This could be caused by outliers in the data, multi-modal distributions, highly exponential distributions, and more.
Conclusion
In the dynamic landscape of machine learning, data encoding plays a pivotal role in transforming raw, diverse data into a format that algorithms can comprehend. From handling categorical variables to representing textual information, various encoding techniques cater to different types of data. A solid understanding of these techniques and their applications is crucial for building robust and accurate machine learning models. As technology advances, the field of data encoding continues to evolve, contributing to the refinement of models and the broader success of machine learning applications.
Please Follow and 👏 Subscribe for the story courses teach to see latest updates on this story
If you want to learn more about these topics: Python, Machine Learning Data Science, Statistic For Machine learning, Linear Algebra for Machine learning Computer Vision and Research
Then Login and Enroll in Coursesteach to get fantastic content in the data field.
Stay tuned for our upcoming articles where we will explore specific topics related to Machine learning with scikit-learn in more detail!
Remember, learning is a continuous process. So keep learning and keep creating and Sharing with others!💻✌️
Note:if you are a Supervised learning with scikit-learn’ export and have some good suggestions to improve this blog to share, you write comments and contribute.
if you need more update about Supervised learning with scikit-learn’ and want to contribute then following and enroll in following
👉Course: Supervised learning with scikit-learn
Source
1- Python Tricks for Data Science
2-Nominal And Ordinal Encoding In Data Science!
3-One Hot Encode in Machine Learning
4-How to handle Categorical variables?
5-One-Hot Encoding, Explained — victorzhou.com(Unread)
6-𝗘𝗻𝗰𝗼𝗱𝗶𝗻𝗴 𝗡𝗼𝗺𝗶𝗻𝗮𝗹 𝗖𝗮𝘁𝗲𝗴𝗼𝗿𝗶𝗰𝗮𝗹 𝗗𝗮𝘁𝗮 𝗶𝗻 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴(Unread)